publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2024
- Under Review
 Enriching Social Science Research via Survey Item LinkingTornike Tsereteli, Daniel Ruffinelli, and Simone Paolo Ponzetto2024
Enriching Social Science Research via Survey Item LinkingTornike Tsereteli, Daniel Ruffinelli, and Simone Paolo Ponzetto2024Questions within surveys, called survey items, are used in the social sciences to study latent concepts, such as the factors influencing life satisfaction. Instead of using explicit citations, researchers paraphrase the content of the survey items they use in-text. However, this makes it challenging to find survey items of interest when comparing related work. Automatically parsing and linking these implicit mentions to survey items in a knowledge base can provide more fine-grained references. We model this task, called Survey Item Linking (SIL), in two stages: mention detection and entity disambiguation. Due to an imprecise definition of the task, existing datasets used for evaluating the performance for SIL are too small and of low-quality. We argue that latent concepts and survey item mentions should be differentiated. To this end, we create a high-quality and richly annotated dataset consisting of 20,454 English and German sentences. By benchmarking deep learning systems for each of the two stages independently and sequentially, we demonstrate that the task is feasible, but observe that errors propagate from the first stage, leading to a lower overall task performance. Moreover, mentions that require the context of multiple sentences are more challenging to identify for models in the first stage. Modeling the entire context of a document and combining the two stages into an end-to-end system could mitigate these problems in future work, and errors could additionally be reduced by collecting more diverse data and by improving the quality of the knowledge base.
@misc{tsereteli2024enrichingsocialscienceresearch, title = {Enriching Social Science Research via Survey Item Linking}, author = {Tsereteli, Tornike and Ruffinelli, Daniel and Ponzetto, Simone Paolo}, year = {2024}, eprint = {2412.15831}, archiveprefix = {arXiv}, primaryclass = {cs.DL}, url = {https://arxiv.org/abs/2412.15831}, } - VADIS – A Variable Detection, Interlinking and Summarization SystemYavuz Selim Kartal, Muhammad Ahsan Shahid, Sotaro Takeshita, and 4 more authorsIn Advances in Information Retrieval. A live demo can be found here , 2024
The VADIS system addresses the demand of providing enhanced information access in the domain of the social sciences. This is achieved by allowing users to search and use survey variables in context of their underlying research data and scholarly publications which have been interlinked with each other.
@inproceedings{10.1007/978-3-031-56069-9_22, author = {Kartal, Yavuz Selim and Shahid, Muhammad Ahsan and Takeshita, Sotaro and Tsereteli, Tornike and Zielinski, Andrea and Zapilko, Benjamin and Mayr, Philipp}, editor = {Goharian, Nazli and Tonellotto, Nicola and He, Yulan and Lipani, Aldo and McDonald, Graham and Macdonald, Craig and Ounis, Iadh}, title = {VADIS -- A Variable Detection, Interlinking and Summarization System}, booktitle = {Advances in Information Retrieval}, year = {2024}, publisher = {Springer Nature Switzerland}, address = {Cham}, pages = {223--228}, isbn = {978-3-031-56069-9}, doi = {https://doi.org/10.1007/978-3-031-56069-9_22}, }


2022
- Overview of the SV-Ident 2022 Shared Task on Survey Variable Identification in Social Science PublicationsTornike Tsereteli, Yavuz Selim Kartal, Simone Paolo Ponzetto, and 3 more authorsIn Proceedings of the Third Workshop on Scholarly Document Processing, Oct 2022
In this paper, we provide an overview of the SV-Ident shared task as part of the 3rd Workshop on Scholarly Document Processing (SDP) at COLING 2022. In the shared task, participants were provided with a sentence and a vocabulary of variables, and asked to identify which variables, if any, are mentioned in individual sentences from scholarly documents in full text. Two teams made a total of 9 submissions to the shared task leaderboard. While none of the teams improve on the baseline systems, we still draw insights from their submissions. Furthermore, we provide a detailed evaluation.
@inproceedings{tsereteli-etal-2022-overview, title = {Overview of the {SV}-Ident 2022 Shared Task on Survey Variable Identification in Social Science Publications}, author = {Tsereteli, Tornike and Kartal, Yavuz Selim and Ponzetto, Simone Paolo and Zielinski, Andrea and Eckert, Kai and Mayr, Philipp}, editor = {Cohan, Arman and Feigenblat, Guy and Freitag, Dayne and Ghosal, Tirthankar and Herrmannova, Drahomira and Knoth, Petr and Lo, Kyle and Mayr, Philipp and Shmueli-Scheuer, Michal and de Waard, Anita and Wang, Lucy Lu}, booktitle = {Proceedings of the Third Workshop on Scholarly Document Processing}, month = oct, year = {2022}, address = {Gyeongju, Republic of Korea}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.sdp-1.29}, pages = {229--246}, } - Preprint
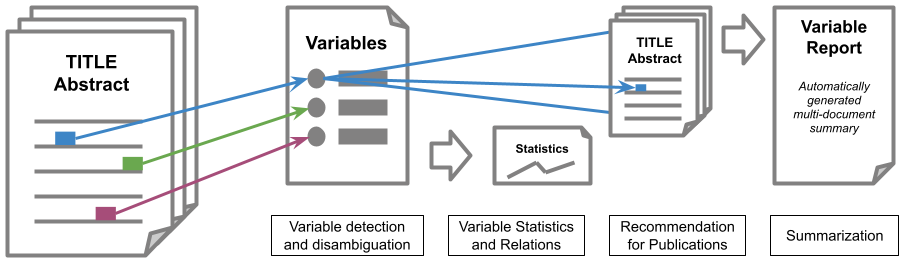 Towards Automated Survey Variable Search and Summarization in Social Science PublicationsYavuz Selim Kartal, Sotaro Takeshita, Tornike Tsereteli, and 6 more authorsOct 2022
Towards Automated Survey Variable Search and Summarization in Social Science PublicationsYavuz Selim Kartal, Sotaro Takeshita, Tornike Tsereteli, and 6 more authorsOct 2022Nowadays there is a growing trend in many scientific disciplines to support researchers by providing enhanced information access through linking of publications and underlying datasets, so as to support research with infrastructure to enhance reproducibility and reusability of research results. In this research note, we present an overview of an ongoing research project, named VADIS (VAriable Detection, Interlinking and Summarization), that aims at developing technology and infrastructure for enhanced information access in the Social Sciences via search and summarization of publications on the basis of automatic identification and indexing of survey variables in text. We provide an overview of the overarching vision underlying our project, its main components, and related challenges, as well as a thorough discussion of how these are meant to address the limitations of current information access systems for publications in the Social Sciences. We show how this goal can be concretely implemented in an end-user system by presenting a search prototype, which is based on user requirements collected from qualitative interviews with empirical Social Science researchers.
@misc{kartal2022automatedsurveyvariablesearch, title = {Towards Automated Survey Variable Search and Summarization in Social Science Publications}, author = {Kartal, Yavuz Selim and Takeshita, Sotaro and Tsereteli, Tornike and Eckert, Kai and Kroll, Henning and Mayr, Philipp and Ponzetto, Simone Paolo and Zapilko, Benjamin and Zielinski, Andrea}, year = {2022}, eprint = {2209.06804}, archiveprefix = {arXiv}, primaryclass = {cs.DL}, url = {https://arxiv.org/abs/2209.06804}, } - Cross-lingual citations in English papers: a large-scale analysis of prevalence, usage, and impactTarek Saier, Michael Färber, and Tornike TsereteliInt. J. Digit. Libr., Jun 2022
Citation information in scholarly data is an important source of insight into the reception of publications and the scholarly discourse. Outcomes of citation analyses and the applicability of citation-based machine learning approaches heavily depend on the completeness of such data. One particular shortcoming of scholarly data nowadays is that non-English publications are often not included in data sets, or that language metadata is not available. Because of this, citations between publications of differing languages (cross-lingual citations) have only been studied to a very limited degree. In this paper, we present an analysis of cross-lingual citations based on over one million English papers, spanning three scientific disciplines and a time span of three decades. Our investigation covers differences between cited languages and disciplines, trends over time, and the usage characteristics as well as impact of cross-lingual citations. Among our findings are an increasing rate of citations to publications written in Chinese, citations being primarily to local non-English languages, and consistency in citation intent between cross- and monolingual citations. To facilitate further research, we make our collected data and source code publicly available.
@article{Saier2022-ej, title = {Cross-lingual citations in English papers: a large-scale analysis of prevalence, usage, and impact}, author = {Saier, Tarek and F{\"a}rber, Michael and Tsereteli, Tornike}, journal = {Int. J. Digit. Libr.}, publisher = {Springer Science and Business Media LLC}, volume = {23}, number = {2}, pages = {179--195}, month = jun, year = {2022}, copyright = {https://creativecommons.org/licenses/by/4.0}, language = {en}, doi = {https://doi.org/10.1007/s00799-021-00312-z}, }


